Intent-aware · Self-healing · Multi-cloud native · No rip and replace
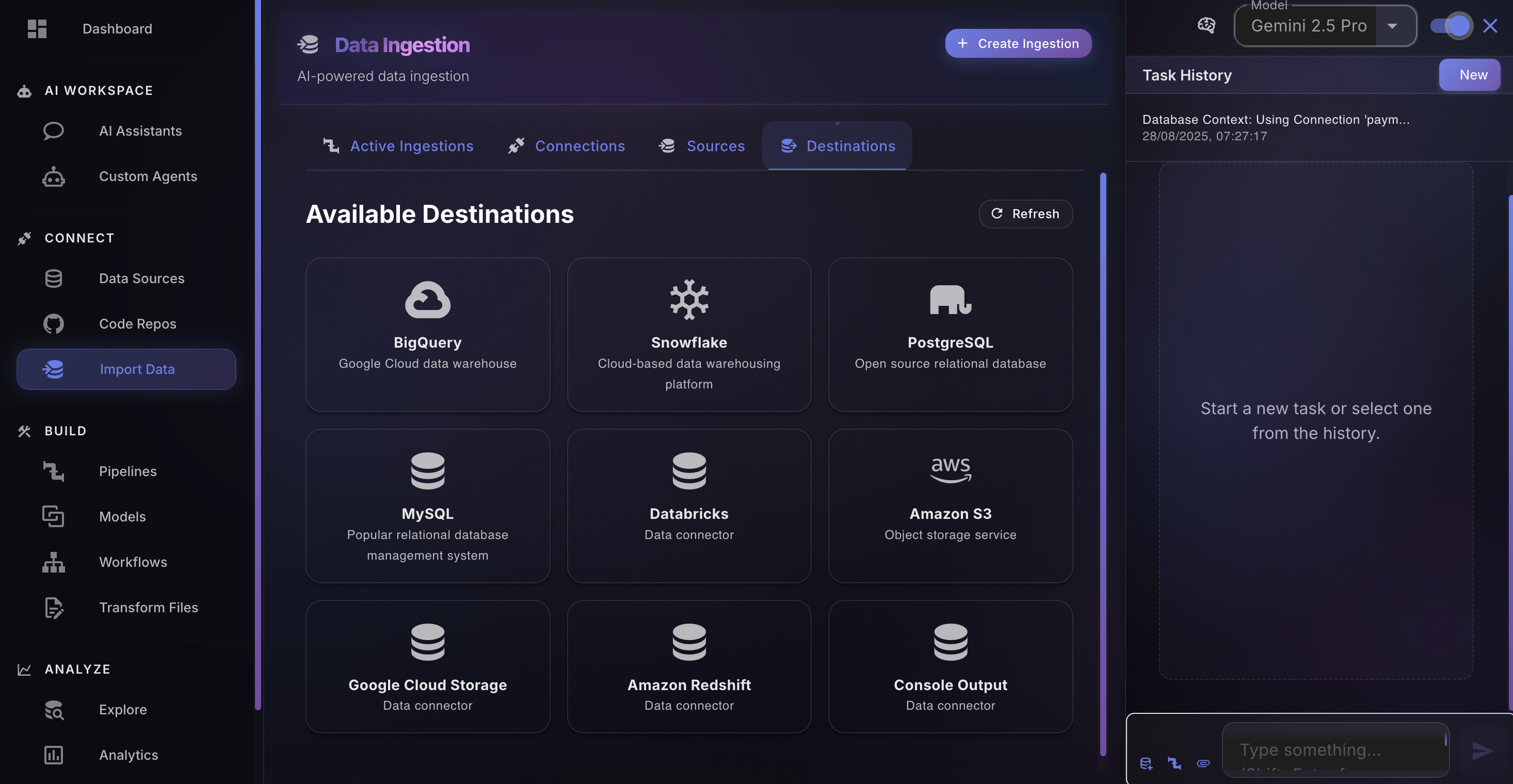
How Dagen Works
Tell Dagen what you want to build. The system handles design, build, deploy, monitor, and heal automatically.
Describe the pipeline in plain language. Dagen derives the architecture and waits for your approval.
Specialist agents handle ingestion, transformation, modeling, quality, and orchestration end-to-end.
Choose Guided, Semi-Autonomous, or Autonomous. Move between levels as trust is established.
Dagen detects schema drift, quality anomalies, and SLA violations — and remediates without paging anyone.
Every pipeline makes the next one faster. Tribal knowledge is captured, not lost when engineers leave.
Platform
Dagen orchestrates specialist agents across the full data engineering lifecycle, from ingestion to business-ready KPIs.
Connect to any source via 500+ included connectors. Databases, APIs, files, or streams. Dagen configures rate limits, retries, and handles source changes automatically; no boilerplate coding required.
Apply business logic, joins, and validations through conversation. Dagen generates dbt models or Spark code, tests, and full documentation aligned to your declared intent.
Dagen monitors schema drift, data quality thresholds, SLA windows, and volume anomalies. When something breaks, it remediates by rewriting transformation code, adjusting ingestion, and reprocessing records. Human-in-the-loop only when autonomous action isn't enough.
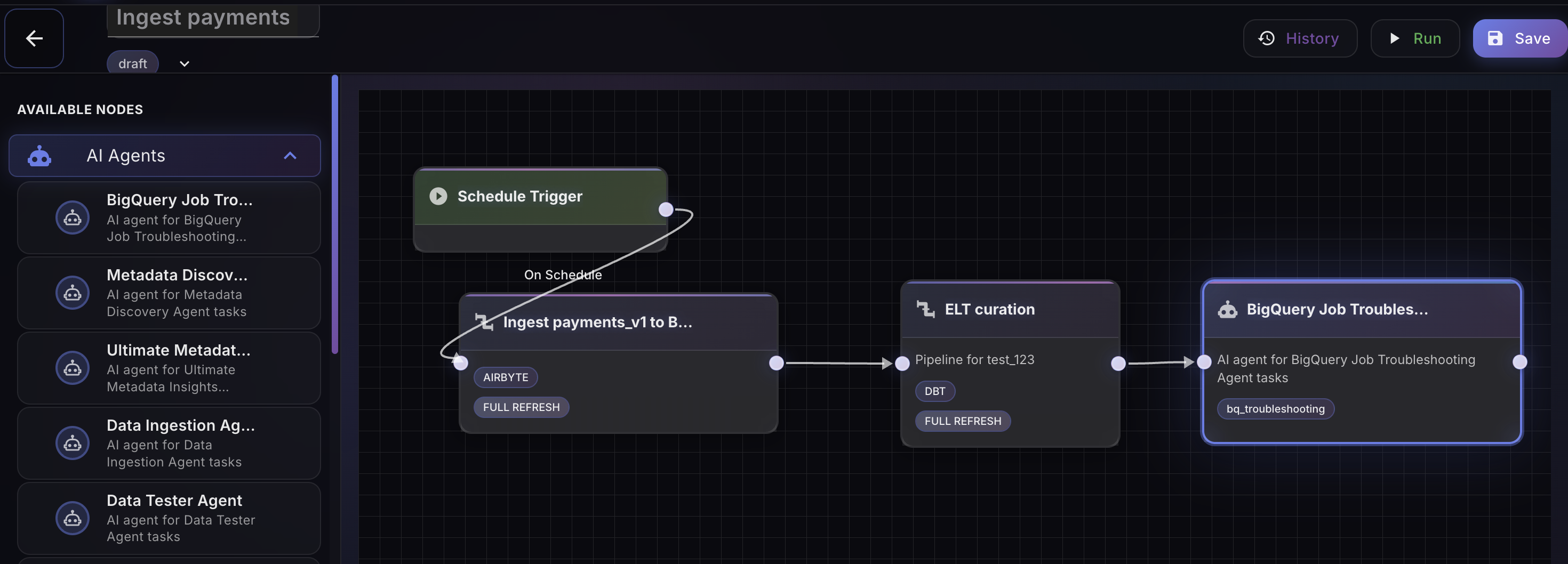
Self-Healing
Dagen monitors every pipeline continuously — schema drift, data quality, SLA windows, volume anomalies, dependency failures. When something breaks, or is about to, the system acts before anyone files a ticket.
DETECTION
Type changed: DECIMAL(10,2) → VARCHAR. 3 downstream dbt models affected.
REMEDIATION IN PROGRESS
Casting applied at bronze layer. dbt tests regenerated. Downstream SLAs preserved.
RESOLVED
Remediation logged to episodic memory. Drift pattern added to monitoring rules.
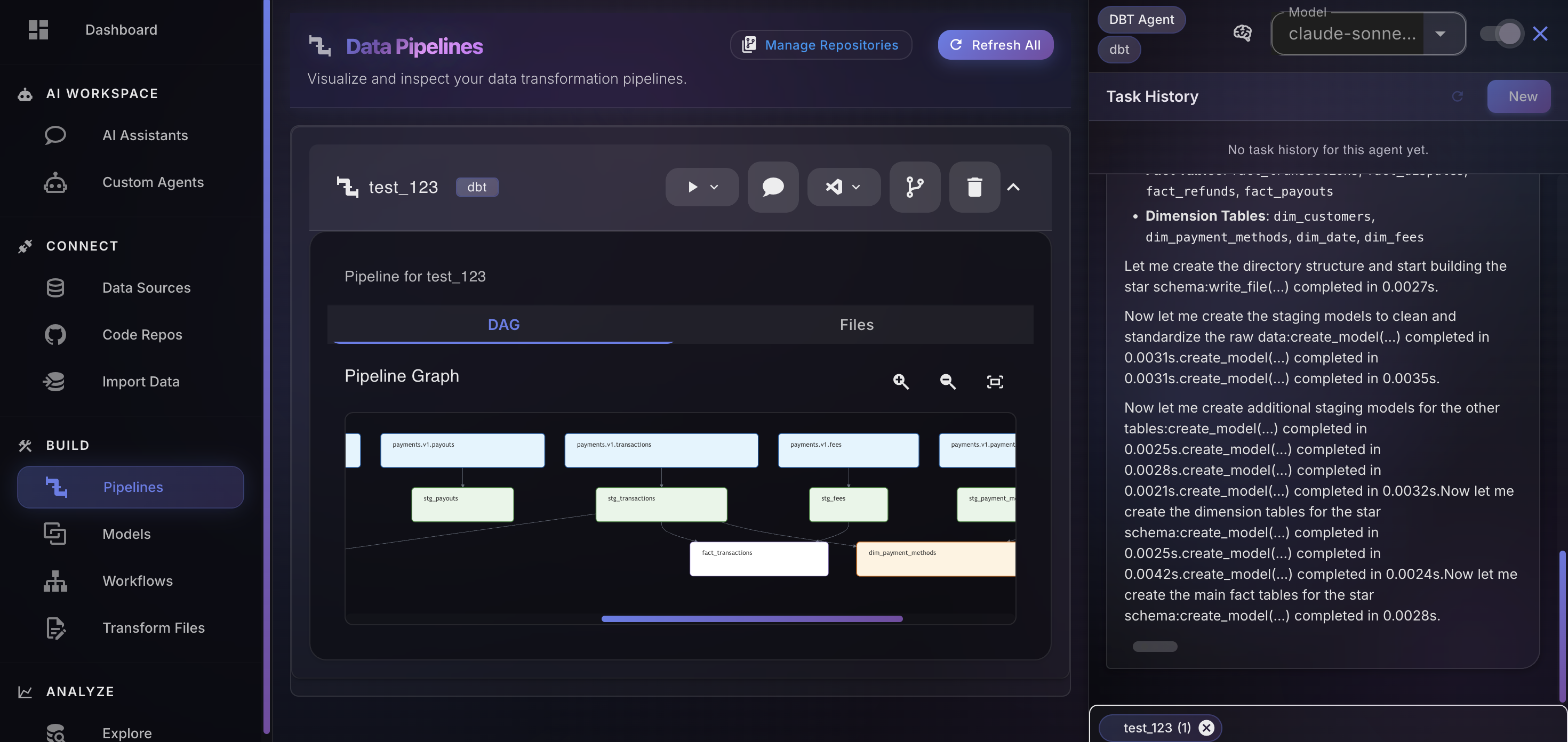
Specialist Agents
Dagen's super-agent orchestrates a hierarchy of specialists each with deep domain knowledge by dispatching the right agent for every task in your pipeline lifecycle.
Configures 500+ connectors. Handles rate limits, retries, and source API changes automatically.
Generates transformation models, tests, and documentation aligned to your declared business intent.
Profiles source data, infers schema semantics, and builds your institutional knowledge base.
Designs medallion architecture layers: bronze ingestion, silver cleansing, gold business-ready KPIs.
Identifies and remediates quality issues according to pipeline-specific rules, not generic thresholds.
Schedules, coordinates, and monitors execution across all pipeline layers and cloud environments.
Writes and optimizes PySpark jobs for large-scale workloads on Databricks, Dataproc, and EMR.
Creates synthetic datasets for pipeline validation and safe development environments.
Enriches pipelines with external data sources, market data, and public datasets on demand.
You Stay in Control
Three operating modes let you calibrate autonomous decision-making to your team's comfort level. Most teams start at Guided and move to Autonomous within 90 days.
Dagen presents options and rationale at every decision point. Engineers remain in full control. Best for teams new to agentic systems or high-sensitivity pipelines.
Dagen handles routine decisions independently and surfaces only architectural choices and significant tradeoffs for human review. The right balance for most production environments.
Dagen executes end-to-end with minimal interruption. Humans are notified only for exceptions, anomalies, or policy violations. For teams that have established trust in the system.
The Compounding Advantage
Dagen's tri-layer memory system transforms every interaction into institutional knowledge. Unlike any point solution, Dagen's value compounds; the longer you use it, the more it understands your data landscape.
The tribal knowledge that typically walks out the door when a senior engineer leaves is instead captured, structured, and made available to every future agent and engineer who touches the system.
The active context for current pipeline tasks: what is being built, what decisions have been made, what exceptions are in flight.
A structured log of best practices directives, rules, remediations, and architectural decisions. Enables accurate and repeatable execution across your entire data estate.
A persistent, organization-specific repository of best practices, architectural preferences, data definitions, and tribal knowledge that accumulates over time and informs every future decision.
Works With Your Stack
Dagen sits alongside your existing tools and cloud providers. Bring your DAGs, your schemas, your warehouses. We add the intelligence layer.
 Snowflake
Snowflake Apache
Kafka
Apache
Kafka Airflow
Airflow Microsoft Azure
Microsoft Azure BigQuery
BigQuery dbt
dbt Apache
Flink
Apache
Flink PostgreSQL
PostgreSQL Power BI
Power BI Databricks
Databricks GitHub
GitHub
 Amazon S3
Amazon S3 Apache
Spark
Apache
Spark Kubernetes
Kubernetes Salesforce
Salesforce MySQL
MySQL Apache Iceberg
Apache Iceberg Teradata
Teradata Google Cloud Storage
Google Cloud Storage Apache
Hive
Apache
Hive Azure Blob Storage
Azure Blob Storage Apache Ozone
Apache Ozone MongoDB
MongoDB
The Current Gap
dbt, Airflow, Spark. Powerful tools, built for a world where pipelines were passive; they
ran, they failed, someone fixed them. That model made sense.
AI workloads have different expectations:
pipelines that understand context, catch anomalies early, and heal without a ticket being filed. The modern
data stack was designed for a different era. One where failures were expected and humans were always in the
loop.
The tools haven't caught up. Yet.
Pipelines complete with exit code 0 while delivering corrupt, incomplete, or stale data to production. Nobody knows until a dashboard looks wrong at 9AM.
Every schema drift, API deprecation, or quality issue still requires a human to detect, diagnose, and fix. At the AI scale - hundreds of sources, thousands of pipelines - that doesn't scale.
The answers to why your pipelines are built the way they are live in the heads of two or three senior engineers. When they leave, the organization regresses. No existing tooling captures this.
A New Era
New pipelines in hours, not days. Dagen doesn't replace Snowflake, Databricks, dbt, or Spark: It makes them smarter. You start by building net-new pipelines with Dagen, moving faster than ever before. Over time, your existing jobs get retrofitted; refactored incrementally to become agentic, context-aware, and self-healing. Your infrastructure stays. It just stops being passive.
| Capability | Legacy ETL | Modern Data Stack | Dagen Agentic Pipelines |
|---|---|---|---|
| Pipeline authoring | Manual, GUI-driven | Manual, code-first | Intent-driven, AI-generated |
| Self-healing | None | None | Native — autonomous remediation |
| Schema drift handling | Manual intervention | Manual intervention | Automated detection & repair |
| Institutional knowledge | None | Partial (dbt docs) | Tri-layer persistent memory |
| AI / RAG data support | Not supported | Retrofitted, partial | Native, first-class |
| Human-in-the-loop | Always required | Most of the time | On exception only |
| Time to first pipeline | Weeks | Days | Hours |
| Learning over time | None | None | Continuous — compounds over time |
Why the next generation of data pipelines must be intent-aware, self-healing, and autonomous by default. The foundational case for the infrastructure shift happening right now.
Early users are already seeing dramatic gains — from eliminating the operational friction that slows data teams down.
Go from data source to production-ready, AI-native pipeline in a single working session — with full documentation, built-in observability, and autonomous monitoring from day one.
